





| ||||||
| ||||||
| ||||||
| ||||||
Содержание
1. Введение.
2. Сегментация. Теоретический подход.
3.Математическая модель сегментации.
4. Общий алгоритм сегментации.
5.Как правильно определить пороговый коэффициент?
Введение
Одна из самых важных задач, систем автоматической обработки речи, это задача сегментации речи.
Для голосовой верификации характерные признаки голоса должны вычисляться на определённых сегментах речевого сигнала. То есть, частота основного тона, присущая диктору, вычисляется на гласноподобных участках сигнала, форма речевого тракта характеризуется формантными частотами, измеряемыми на известных гласных звуках, скорость артикуляции определяется по длительностям переходных процессов между артикуляторно-акустическими сегментами. Сегментация также необходима при решении обратной задачи — восстановления формы речевого тракта по акустическому сигналу , которая может быть использована в следующих областях: системы сжатия и передачи речи в мобильной телефонии , системы автоматического распознавания речи, системы обучения иноязычному произношению.
В исследовательских системах и на этапе предварительной разработки возможно использование ручной сегментации. В отличии от автоматической сегментации она требует намного больше затрат сил и времени: во-первых, в слитной речи нет пауз между словами, во-вторых, коартикуляция, возникающая и на границе последовательно производимых звуков, которая существенно облегчает правильное восприятие и понимание речи, но затрудняет задачу поиска границ сегментов. К тому же, это считается практически невозможно точно воспроизвести результаты ручной сегментации. Одной из причин является субъективность слухового и зрительного восприятия человека.
Проблем данного характера не возникает при автоматической сегментации, которая тоже может давать ошибочные результаты, но всегда воспроизводимые.
В своей работе я рассматриваю сегментацию с помощью спектрального анализа, на базе дискретного вейвлет-преобразования. Так как спектральный анализ является одним из эффективных методов, которые применяются с целью извлечения информации из речевых сигналов. В случае распознавания речи, он в основном используется для повышения точности параметризации. Анализ энергии в различных подзонах частоты дает возможность различить начало и конец фонем. На многих границах, нет никакого заметного падения общей энергии, а на некоторых частотах, энергия, в целом постоянна на протяжении всей фонемы. Но несмотря на это, многие фонемы резко изменяются в частотном диапазоне. Это и позволяет определять их начальные и конечные точки. Данный метод отличается от множества других тем, что он анализирует сам сигнал в частотной области, не используя при этом информацию, основанную на моделировании или уже распознанные фонемы. Сегментационный шаг может проводится независимо и заканчиваться перед шагом распознавания. Обучение, адаптация к пользователю здесь не требуется.
Сегментация. Теоретический подход.
Речевой сигнал состоит из квазистационарных участков, соответствующих голосовым и шипящим фонемам, перемежаемых участками со сравнительно быстрыми изменениями спектральных характеристик сигнала (межфонемные переходы, взрывные и смычные фонемы, внутрисловные переходы речь-пауза). Спектральные особенности сигнала, определяемые передаточной характеристикой речевого тракта, изменяющейся в процессе артикуляции играют значительную роль для анализа речи, в пределах стационарных участков. Поэтому спектральный анализ и вейвлет – преобразование будут весьма эффективными методами для анализа речевого сигнала.
Применяя вейвлет-преобразования мы можем судить не только о частотном спектре сигнала, но и о том в какой момент времени появилась данная гармоника. Это основное преимущество над преобразованием Фурье. С помощью гармоник можно легко анализировать прерывистые сигналы, либо сигналы с острыми всплесками. Также, вейвлеты позволяют анализировать данные согласно масштабу, на одном из заданных уровней (мелком или крупном). То есть, если требуется анализ и обработка сигналов и функций, которые нестационарные во времени и неоднородные в пространстве, когда в результате нам нужно получить по мимо частотной характеристики, сведения об определённых гармониках, то тогда нужно применять вейвлетное преобразование.
Обычно структурной единицей речи является фонема, именно поэтому задача сегментации сводится к обнаружению межфонемных переходов Так как, на межфонемных переходах сигнал претерпевает значительные изменения сразу на многих масштабах исследования, и, соответственно, характеризуется возрастанием вейвлет - коэффициентов для большинства уровней детализации, в то время как на стационарных участках фонем вейвлет-коэффициенты оказываются сгруппированными вблизи определенных масштабов. Таким образом, поиск межфонемных границ обычно сводится к отысканию моментов увеличения вейвлет-коэффициентов на значительном количестве уровней масштабирования.
Математическая модель сегментации.
Вейвлет-разложение речевого сигнала длины N отсчётов представляет собой сумму:
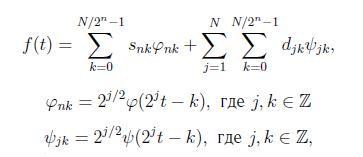
где n – количество уровней декомпозиции, snk,djk – коэффициенты аппроксимации и детализации вейвлет-разложения, j – скейлинг (масштабная) функция, y – базисный (материнский) вейвлет.
Так как вейвлет-коэффициенты аппроксимации соответствуют передаточной характеристике фильтра низких частот, а детализации — высокочастотному фильтру, то речевой сигнал рассматривается в различных частотных диапазонах.
Самый низкий используемый частотный диапазон 125Гц. Диапазоны ниже не содержат информации, важной для задачи сегментации. Причина этого заключается в субъективности человеческой речи, охватывающая интервал от 150 Гц до 4000 Гц. Таким образом, сигнал обычно разлагается на 6 уровней.
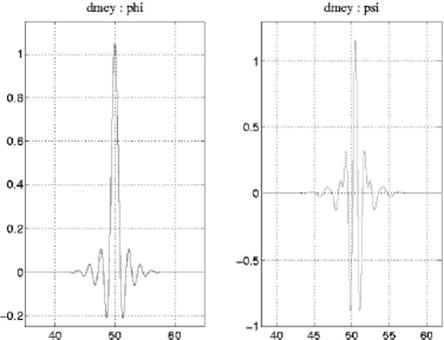
Рис.1. Дискретный вейвлет Мейера
К слову, абсолютная величина скорости изменения энергии, которая велика в начале и в конце фонем, не однозначно определяет начальные и конечные точки, по двум причинам. Во-первых, энергия может повыситься в течение значительного периода времени в начале фонемы, что приводит к неоднозначности время запуска. Во-вторых, может также быть быстрым изменения энергии в середине сегмента. Лучший метод определения границ фонем опирается на энергетические переходы между ДВП участками.
Количество 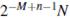 образцов вейвлет спектров n-уровня (где n = 1, ..., М) зависит от длины N речевого сигнала во временной области, предполагая, что N является степенью 2. Ниже, в таблице 1, приведён пример их количества на каждом уровне по отношению к низкому уровню разрешения. Для каждого n-уровня разложения энергия сигнала
образцов вейвлет спектров n-уровня (где n = 1, ..., М) зависит от длины N речевого сигнала во временной области, предполагая, что N является степенью 2. Ниже, в таблице 1, приведён пример их количества на каждом уровне по отношению к низкому уровню разрешения. Для каждого n-уровня разложения энергия сигнала
 (5)
(5)
рассчитывается по-другому, чтобы получить равное количество образцов.
Энергия ДВП участка показывает быстрые изменения. Несмотря на сглаживание изменение энергетических форм волны быстрое. Первые порядковые отличия в энергии неизбежно шумны, и так вычисляя порог 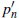 , для энергетических колебаний в каждой подгруппе, выбирая самые высокие значения
, для энергетических колебаний в каждой подгруппе, выбирая самые высокие значения 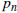 в окне данного размера
в окне данного размера 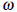 , чтобы получить энергетический порог. Дополнительно используется сглаженный оператор, разность которого вычисление энергетического участка сворачивается с маской [1,2, -2, -1] для получения сглаженной информации об изменении
, чтобы получить энергетический порог. Дополнительно используется сглаженный оператор, разность которого вычисление энергетического участка сворачивается с маской [1,2, -2, -1] для получения сглаженной информации об изменении 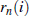 (скорость изменения энергии).
(скорость изменения энергии).
Таблица 1: Характеристика дискретного вейвлет преобразования уровней
| ДВП уровень | Частотный диапазон (Гц) | Количество образцов по сравнению с уровнем 1 | Размер окна |
| 6 | 2756-5512 | 32 | 3 |
| 5 | 1378-2756 | 16 | 3 |
| 4 | 689-1378 | 8 | 3 |
| 3 | 345-689 | 4 | 5 |
| 2 | 172-345 | 2 | 5 |
| 1 | 86-172 | 1 | 5 |
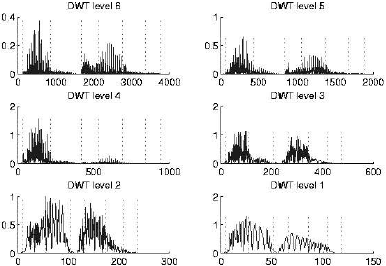
Рис.2. Энергия ДВП участков имени "Андрей". Пунктирные линии - границы ручной сегментации
Начало фонем обычно обозначены изначально небольшим, но быстро растущим уровнем энергии в одном или нескольких ДВП уровнях. Граница фонемы может быть обнаружена путём поиска i-й точки.
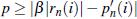
Где постоянная р – значение порога, который дает отчет о масштабе времени и чувствительности контрольно-пропускных пунктов. По скорости изменения функции  умножается на коэффициент масштабирования
умножается на коэффициент масштабирования 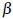 равный 1. На практике мы ищем индексы, для которых сглаженная энергия и скорости изменения функции подхода близки друг к другу и не обязательно пересекающихся. Известно, что порог р – расстояние между энергией и сглаженной скоростью изменения функции измеряется как 0,02 для достижения наилучших результатов. Другим условием повышения точности превышения минимального порога
равный 1. На практике мы ищем индексы, для которых сглаженная энергия и скорости изменения функции подхода близки друг к другу и не обязательно пересекающихся. Известно, что порог р – расстояние между энергией и сглаженной скоростью изменения функции измеряется как 0,02 для достижения наилучших результатов. Другим условием повышения точности превышения минимального порога 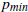 из участка ДВП энергии, которая была выбрана экспериментально 0.003. Это гарантия анализа именно речевого сигнала, а не шумового участка
из участка ДВП энергии, которая была выбрана экспериментально 0.003. Это гарантия анализа именно речевого сигнала, а не шумового участка
Общий алгоритм сегментации.
На разных уровнях, положение границ может различаться. Всё это объясняется природой вейвлет-преобразования — рассмотрение сигнала на различных частотных диапазонах. То есть для одной части фонем только один из уровней покажет значительное изменение энергии, но для остальных — несколько. Таким образом, сначала на каждом уровне определяется только часть переходов между фонемами и затем результат сгруппировывается. При этом межфонемный интервал не может быть менее порогового значения — минимальной длительности фонемы.
Обычно значение порога приблизительно равно 25 мсек.
1. Предобработка сигнала. В процессе предобработки сигнал нормализуется: все отсчёты делятся на максимальное значение, для установки единых пороговых значений для любых входных сигналов.
2. Входной сигнал разбивается на уровни по 256 отсчётов при частоте дискретизации 16 кГц с перекрытием от 25% до 50%.
3. Каждый уровень накрывается окном Хэмминга для устранения дефектов на краях.
4. К каждому уровню применяется вейвлет-преобразование. Используется разложение до 6-го уровня декомпозиции.
5. Для каждого уровня декомпозиции определяется энергия, как сумма квадратов значений коэффициентов детализации  .
.
6. Так как энергия сильно меняется от уровня к уровню из-за неизбежного шума, необходимо сглаживание. Для этого вычисляется усреднённая энергия 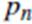 для каждого уровня декомпозиции, заменяя значение энергии
для каждого уровня декомпозиции, заменяя значение энергии
на максимальное Pmax для каждых 3 на первых трёх, и на каждых 5 для последующих уровней детализации.
7. Для определения скорости изменения энергии вычисляется производная .
8. Критерии выбора границ фонем:
Учитывая порог р расстояние между и (i) и порог минимального (i), найти индексы для которых 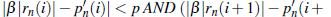
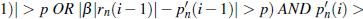 , где = 1.
, где = 1.
9. Для объединения результатов расстановки границ между уровнями все индексы объединяются в один вектор. Чтобы избежать ложных границ, устанавливается минимальный интервал фонемы — a.
10. Рассчитать среднее значение индекса (с округлением до ближайшего целого числа) для каждой группы находящихся в предыдущем шаге, как представитель группы. Они индексируют фонемные границы в порядке индексации ДВП 1-го уровня.
Как определить оптимальный пороговый коэффициент?
Проводились исследования результатов работы описанного алгоритма при разном пороговом коэффициенте для определения его оптимального значения.
Результаты эксперимента приведены в таблице 1.
Таблица 1. результаты фонемной сегментации в зависимости от значения порогового коэффициента
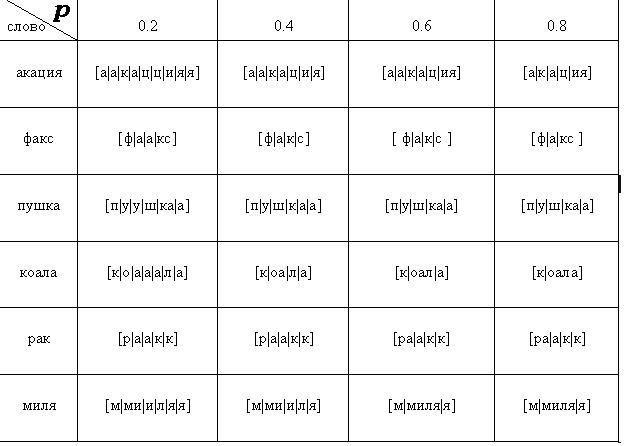
Из результатов эксперимента видно, что с увеличением порогового коэффициента уменьшается чувствительность алгоритма к изменениям речевого сигнала. Так, при значениях 0.2-0.4 заметно выделение лишних сегментов для гласных. При этом хорошо разделяются голосовые звуки, стоящие рядом -оа-, -ия- , разделяется сочетание -кс-. При больших значениях p количество лишних сегментов мало, но перестают разделяться голосовые звуки и сочетание “к” с шипящим.
К тому же качество сегментации очень сильно зависит от фонемного состава речевого сигнала. Например, для слова “факс” наилучший результата достигается при значении порогового коэффициента p= 0.4, для слова “акация” - 0.8. Таким образом для оптимальной работы представленного алгоритма необходимо изменять p, т.е. сделать его адаптивным.
Заключение
Данный метод сегментации основан на дискретном вейвлет-преобразовании. Метод является одним из эффективных, так как речевой сигнал характеризуется изменениями уровней энергии, которые проявляются только в узком диапазоне частот. Именно поэтому границы вероятнее детектировать, анализируя значения энергий поддиапазонов вейвлет-разложения, а не сигнала в целом как в случае преобразований, основанных на Фурье анализе. В качестве основного параметра определения точной границы сегмента используется скорость изменения энергии при последующем объединении результатов расстановки границ между уровнями детализации.
Список литературы:
1. Сорокин В.Н., Цыплихин А.И. Сегментация и распознавание гласных // Информационные процессы. 2004. т.4, № 2.
2. О.А. Вишнякова, Д.Н. Лавров АВТОМАТИЧЕСКАЯ СЕГМЕНТАЦИЯ РЕЧЕВОГО СИГНАЛА НА БАЗЕ ДИСКРЕТНОГО ВЕЙВЛЕТ-ПРЕОБРАЗОВАНИЯ //Математические структуры и моделирование 2011, вып. 23, с. 43–48
3. Bartosz Zi.ołko WAVELET METHOD OF SPEECH SEGMENTATION//Proceedings of 14th European Signal Processing Conference EUSIPCO. 2006. (в переводе Костенко А.В.)
 (zip - application/zip)
(zip - application/zip)