Реферат
по курсу «Теория вероятностей и математическая статистика»
для студентов по направлению 090900 – Информационная безопасность
на тему: «Формирование фонетической базы данных из речевого сигнала на основе информационной теории восприятия речи»
Преподаватель: Владимир Васильевич Савченко
Выполнил: студент НГЛУ Факультета Международных Отношений, Экономики и Управления
группы 105Б Соков К.П.
Содержание
1. Постановка задачи
2. Обзор подходов к решению.
3. Теоретико-вероятностный (информационный) подход
4. Практическое использование
5. Список литературы
1.Постановка задачи
В современных условиях информационного общества с каждым днем все более актуальным становится использование речевых технологий, таких как, например, распознавание, анализ речи, голосовое управление сложными техническими системами. Данные технологии широко используются при построении справочных и поисковых систем, систем интерактивного обучения иностранным языкам или постановки произношения у глухих или слабослышащих детей, создании разнообразных речевых корпусов, предназначенных как для исследовательских целей (например, сопоставлении различных диалектов), так и для предварительного обучения систем распознавания и синтеза речи.
Одним из основных направлений развития речевых технологий можно считать задачу автоматического распознавания речи (АРР). Для ее решения в настоящее время применяются методы, основанные на искусственных нейронных сетях.
Большинство современных речевых корпусов сопровождается транскрипцией речевых единиц, т.е. их описанием через последовательность фонем. Основной проблемой при формировании речевых корпусов является вариативность речи дикторов, ее составляющих. В связи с этим до настоящего времени не создано ни одной эффективной системы автоматического выделения списка речевых единиц из слитной речи[3].
Следующим направлением применения автоматического анализа речи является задача постановки произношения с визуализацией результатов, которая предполагает использование компьютеров или других специализированных вычислительных устройств помощи в обучении произношению. Обучение произношению с использованием компьютерных систем проводится как на уровне отдельных звуков, так и на более высоких уровнях (отдельные слова, фразы и даже небольшие диалоги).
2. Обзор подходов к решению
Основной подход к решению этой задачи заключается в сравнении речи обучаемого с эталонным. Сложность сравнения состоит в том, что речь человека может меняться в зависимости от различных факторов(настроения, степени усталости и т.п.). Кроме того полученные результаты достаточно сложно интерпретировать, так как нет простого соответствия между движениями лица и записываемыми результатами.
Рассмотрим основные подходы к решению данной проблемы и выберем наиболее эффективный.
Очевидно что метод простого перебора морфем непрактичен в виду большого объема словаря эталонов. Например, для того, чтобы распознать звук “а” диктора, мы будем перебирать все звуки и, получая в конечном итоге тот, чьи параметры наиболее схожи с произносимым звуком. Если скорость идентифицирования одной морфемы и можно считать хорошей, то совсем по-другому дело обстоит со словами, состоящих из нескольких морфем.
По-другому же совсем выглядит система, сочетающая словарь слов и их соответствующее произношение, так как чаще в речи всё же употребляются слитная речь в виде целых слов. Так, разбивая слово на отдельные части(кластеры), предполагая, что это есть отдельные звуки и сравнивая с эталонными морфемами можно определить, что это за слово. Графически его можно представить в виде древа. Это и есть теоретико-вероятностный подход, рассмотрим его подробнее.
3.Теоретико-вероятностный (информационный) подход
В настоящее время наиболее распространенным подходом при решении данных задач анализа и распознавания речи является статистический подход. В его рамках речевые единицы представляются гауссовой моделью сигналов и моделируются набором классов. Подобный подход имеет ряд существенных недостатков, таких как недостаточно высокая точность и надежность. Для устранения указанных недостатков профессором В.В.Савченко была разработана новая информационная теория восприятия речи, основной которой служит критерий минимального информационного рассогласования (МИР) и кластерная модель речевых единиц. Главное преимущество нового подхода состоит в строгом определении понятия «речевая единица» - фонемы как элемента звукового строя национального языка через множество  одноименных звуков-реализаций, объединенных друг с другом в кластер по критерию минимума информационного рассогласования в метрике Кульбака-Лейблера. Jr – конечный объем r-го множества. При этом каждая фонема-кластер математически определяется вектором
одноименных звуков-реализаций, объединенных друг с другом в кластер по критерию минимума информационного рассогласования в метрике Кульбака-Лейблера. Jr – конечный объем r-го множества. При этом каждая фонема-кластер математически определяется вектором  авторегрессионых коэффициентов ar,i своего информационного центра. Он выполняет роль эталона произношения r-го элемента звукового строя языка. А набор центров
авторегрессионых коэффициентов ar,i своего информационного центра. Он выполняет роль эталона произношения r-го элемента звукового строя языка. А набор центров 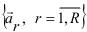 всех R фонем и определяет общий эталон. Информационный центр может быть разным в зависимости от диктора, так как у разных дикторов разное строение голосового аппарата. Получается, что каждый отдельный диктор будет иметь свой собственный ряд эталонных речевых единиц(ЭРЕ). И самым эффективным выходом будет сравнение речевой единицы с группой эталонов разных дикторов.
всех R фонем и определяет общий эталон. Информационный центр может быть разным в зависимости от диктора, так как у разных дикторов разное строение голосового аппарата. Получается, что каждый отдельный диктор будет иметь свой собственный ряд эталонных речевых единиц(ЭРЕ). И самым эффективным выходом будет сравнение речевой единицы с группой эталонов разных дикторов.
Задача существенно упрощается, если воспользоваться гауссовой (нормальной) аппроксимацией закона распределения речевого сигнала на интервалах его стационарности  вида
вида  , где
, где  - автокорреляционная матрица (АКМ) размера
- автокорреляционная матрица (АКМ) размера  . Задача формулируется как проверка простых гипотез о законе распределения ЭРЕ. А соответствующий набор оптимальных решающих статистик может быть записан следующим образом:
. Задача формулируется как проверка простых гипотез о законе распределения ЭРЕ. А соответствующий набор оптимальных решающих статистик может быть записан следующим образом:
 [2]
[2]
где  - это выборочная оценка АКМ анализируемого сигнала
- это выборочная оценка АКМ анализируемого сигнала  . Решение принимается в пользу гипотезы
. Решение принимается в пользу гипотезы  по признаку минимума
по признаку минимума  -ой решающей статистики, т.е.
-ой решающей статистики, т.е.
 [2]
[2]
Причем, в задачах с априорной неопределенностью вместо неизвестных, в общем случае, фонемных АКМ  в выражение (1) подставляют их статистические оценки, которые предварительно получают по R (число фонем в списке) классифицированным выборкам речевого сигнала. Это стандартная формулировка критерия МИР с обучением.
в выражение (1) подставляют их статистические оценки, которые предварительно получают по R (число фонем в списке) классифицированным выборкам речевого сигнала. Это стандартная формулировка критерия МИР с обучением.
При  , и при распределении сигнала
, и при распределении сигнала  с обратной АКМ
с обратной АКМ  ленточной структуры оптимальный алгоритм (2) сводится к минимизации выражения
ленточной структуры оптимальный алгоритм (2) сводится к минимизации выражения
 [2]
[2]
Это формулировка критерия МИР на основе авторегрессионной модели речевого сигнала. Здесь введено обозначение , где
, где  – выборочная оценка спектральной плотности мощности (СПМ) входного сигнала
– выборочная оценка спектральной плотности мощности (СПМ) входного сигнала  в функции дискретной частоты f, а
в функции дискретной частоты f, а  – СПМ эталона r-ой фонемы
– СПМ эталона r-ой фонемы  ; F – верхняя граница частотного диапазона речевого сигнала или используемого канала связи.
; F – верхняя граница частотного диапазона речевого сигнала или используемого канала связи.
Главное достоинство этой модели состоит в возможности предварительной нормировки речевых сигналов по дисперсиям их порождающих процессов. Применительно к сигналам типа ЭРЕ такая нормировка обусловлена физическими особенностями голосового механизма человека: воздушный поток на входе его модели «акустической трубы» имеет приблизительно одну и ту же интенсивность на интервалах, длительностью в целое слово или даже фразу. При учете этого свойства выражение (3) приобретает предельно простой вид:
 [2]
[2]
Предыдущие два выражения представляют собой стандартную формулировку метода обеляющего фильтра в частотной области. Здесь выражение в числителе определяет квадрат амплитудно-частотной характеристики r-го обеляющего фильтра, настроенного на r-ю фонему  . Преимуществом такой интерпретации принципа МИР является, прежде всего, возможность его практической реализации в адаптивном варианте на основе быстрых вычислительных процедур авторегрессионного анализа. Задача в общем случае сводится к двухэтапной проверке статистических гипотез. Первый этап – распознавание ЭРЕ в виде отдельных фонем. На втором этапе распознаются слова и фразы как структурированные последовательности разных фонем. [2]
. Преимуществом такой интерпретации принципа МИР является, прежде всего, возможность его практической реализации в адаптивном варианте на основе быстрых вычислительных процедур авторегрессионного анализа. Задача в общем случае сводится к двухэтапной проверке статистических гипотез. Первый этап – распознавание ЭРЕ в виде отдельных фонем. На втором этапе распознаются слова и фразы как структурированные последовательности разных фонем. [2]
Для первого этапа для начала нужно разделить речевой сигнал на множество x={x1,…, xn} конечного объема n.Сам алгоритм сводится к последовательной проверке условия  . При несоблюдении которого в множество
. При несоблюдении которого в множество  добавляется новая фонема x(R+1)*. Здесь
добавляется новая фонема x(R+1)*. Здесь  - допустимый уровень информационного рассогласования. Для того, чтобы выделить в полученном множестве X* наиболее четкие фонемы вводится дополнительное условие:
- допустимый уровень информационного рассогласования. Для того, чтобы выделить в полученном множестве X* наиболее четкие фонемы вводится дополнительное условие:  . Здесь Vr - число отсчетов в векторе r-й фонемы
. Здесь Vr - число отсчетов в векторе r-й фонемы  ; V0 – пороговый уровень для минимального числа отсчетов в результирующем списке фонем. Полученное в результате множество R и следует считать результатом обработки речи на первом этапе. [2]
; V0 – пороговый уровень для минимального числа отсчетов в результирующем списке фонем. Полученное в результате множество R и следует считать результатом обработки речи на первом этапе. [2]
Распознавание слов по методу обеляющего фильтра в общем случае реализуется на основе многоканальной обработки, в которой число каналов R определяется количеством слов-эталонов. При этом в каждом r-м канале используется набор из  обеляющих фильтров, настроенных на последовательные фонемы соответствующего эталонного слова. Решение принимается по критерию минимума суммы решающих статистик по всем L сегментам анализируемого слова.
обеляющих фильтров, настроенных на последовательные фонемы соответствующего эталонного слова. Решение принимается по критерию минимума суммы решающих статистик по всем L сегментам анализируемого слова.
 [2]
[2]
4.Практическое использование
Как уже говорилось ранее, данная система может иметь множественные практические применения. Она востребована как в социологической, так и в коммерческой области. В частности она может быть использована для голосового управления в системах подобных “Умному дому”, либо же в рядовых настольных ПК. Однако, следует выделить особо важные примеры использования. Так, например, АРР может быть использована для обучения людей, страдающих проблемами со слухом или произношением, и улучшения качества произношения их речи.
Под руководством проф. В.В. Савченко, Акатьева Д.Ю. и Губочкина И.В. был проведен эксперимент по обучению глухих и слабослышащих людей правильному произношению различных фонем. Занятия проходили следующим образом:
Вначале для каждой фонемы было записано по одному информационному центру-эталону от диктора-мужчины с нормальным слухом и произношением. Затем к информационным центрам были дополнительно добавлены эталоны от группы дикторов с нарушениями слуха, но поставленным произношением (дети в возрасте от 9 до 14 лет – 3 мальчика и 5 девочек).[1]
После формирования базы эталонов был осуществлен второй этап экспериментальных исследований. Для этого была сформирована контрольная группа обучающихся из 5 человек (дети с нарушениями слуха в возрасте от 10 до 13 лет – 2 мальчика и 3 девочки).
| № урока | Звуки |
| 1 | «а», «о», «у», «с» |
| 2 | «а», «о», «у», «с» |
| 3 | «в», «и», «э», «к» |
| 4 | «в», «и», «э», «к» |
Обучение проходило в виде индивидуальных занятий длительностью 10 – 15 минут. Каждое занятие состояло из двух частей. В первой части происходило обучение набору из нескольких звуков. Для этого обучаемый многократно произносил заданную фонему, добиваясь максимального приближения своего произношения к эталонному.
В следующей таблице приведены результаты качества произношения по каждому уроку.
| Урок Диктор | До обучения | 1 | 2 | 3 | 4 |
| 1 | 0,29 | 0,24 | 0,28 | 0,15 | 0,17 |
| 2 | 0,52 | 0,46 | 0,57 | 0,46 | 0,47 |
| 3 | 0,55 | 0,54 | 0,49 | - | 0,46 |
| 4 | 0,46 | 0,42 | 0,403 | 0,37 | 0,40 |
| 5 | 0,37 | 0,34 | 0,31 | 0,24 | 0,30 |
Видно, что первый диктор достиг максимального качества при обучении речи. А наихудшие показатели – у второго и третьего дикторов. Но нельзя не отметить, что всего за 4 занятия были получены столь положительные результаты.
Для иллюстрации сказанного ниже приводится диаграмма «траектории обучения» первого диктора на примере фонемы «а». [2]


На левой диаграмме показаны результаты диктора на первом уроке, на правой – результаты того же диктора на втором. Здесь синими стрелками отображено положение эталонов, а красными – результаты обучения. Корректируя свое произношения в соответствии с результатами, выдаваемыми системой, диктор в процессе обучения постепенно приближается к эталону.
Видно, что в процессе обучения существенно уменьшилась вариативность произношения диктора. Аналогичные результаты были получены и для других дикторов из контрольной группы.
5.Список литературы:
1. Савченко В.В. , Автоматизированная система обучения речи на основе теоретико-информационного подхода / В.В. Савченко, Д.Ю. Акатьев, И.В. Губочкин // Исследовано в России, 1243-1252, 2009. http://zhurnal.ape.relarn.ru/articles/2009/099.pdf
2. Савченко В.В. , Результаты натурных испытаний автоматизированной системы обучения речи слабослышащих на основе информационной теории / В.В. Савченко, Д.Ю. Акатьев, И.В. Губочкин // Исследовано в России, 1441-1449, 2009. http://zhurnal.ape.relarn.ru/articles/2009/109.pdf
3. Губочкин И. В., Разработка алгоритмов анализа и распознавания речи на основе адаптивной кластерной модели и критерия минимального информационного рассогласования /Диссертация 2011г.
4. А. В. Савченко, Автоматическое распознавание речи, распознавание образов, распознавание с обучением, критерий минимума информационного рассогласования, генетический алгоритм./2009г.
 (zip - application/zip)
(zip - application/zip)